Inteligență artificială degenerativă
Când, în 2007, după câțiva ani de cercetări intense, am publicat primul meu studiu folosind o metodă AI – Using artificial neural networks to predict the presence of overpressured zones in the Anadarko Basin, Oklahoma – colegii din departament s-au mirat profund, adoptând o poziție de maximă surpriză și reticență în același timp: Ce fel de struțo-cămilă mai este și chestia asta, AI?! Ei nu auziseră până atunci nimic și pe nimeni care ar fi putut, cu ajutorul AI, să rezolve una din cele mai importante probleme care poate apărea în forajele pentru petrol și gaze în bazinele sedimentare din întreaga lume: erupțiile catastrofale produse de penetrarea unor zone cu fluide suprapresurizate (lucrarea mea a devenit de actualitate doar după trei ani, când a avut loc explozia și erupția platformei de foraj Deep Horizon, aprilie 2010, Golful Mexic). Reacția colegilor mei americani a fost similară cu cea din 2010 a colegilor români de la universitățile din Iași și Cluj-Napoca. Nici ei nu auziseră nimic și pe nimeni care să le descrie noua revoluție tehnologică din SUA – fracturarea hidraulică de mare volum a argilelor gazifere. Este adevărat că pseudo-documentarul Gasland nu fusese încă piratat și tradus pe YouTube, nici sintagma „gaze de șist” nu fusese inventată după modelul francez. După Gasland însă, foarte mulți români (nu doar geologi) s-au trezit, precum Monsieur Jourdain, că de fapt și ei pot vorbi, scrie sau comenta despre „fracking”, având „specializări” obținute pe repede-înainte la mari „universități” precum Google, Wikipedia sau YouTube.
Pentru că am intuit că viitorul geoștiințelor va avea o importantă componentă AI, am continuat cercetările mele predictive folosind algoritmi genetici, mașini cu suport vectorial, logică fuzzy etc. și publicând, până în prezent, două cărți (2015, 2024) și mai multe articole peer-reviewed. Perioada aceasta (2007-2024) a fost dominată de metode și algoritmi de inteligență artificială predictivă (Pred-AI). Folosind baze de date numerice pre-existente, eu și/sau studenții mei am controlat direct antrenamentul, verificarea și aplicarea soluțiilor AI pentru predicția unor proprietăți specifice și integrarea apropriată a mai multor discipline (geologie, geofizică, geochimie, mineralogie, ingineria rezervoarelor de apă, petrol sau gaze etc.)
Începând din toamna anului 2022, odată cu lansarea programului ChatGPT, arborele AI s-a consolidat cu o nouă ramură: inteligența artificială generativă (Gen-AI). Spun „s-a consolidat” pentru că aplicațiile Gen-AI există de zeci de ani sub diferite forme, cum ar fi Generative Adversarial Networks (GANs) și VariationalAutoencoders(VAEs), dar capacitățile lor limitate nu au atras mai devreme interesele marilor jucători din liga AI.
ChatGPT și zecile de clone care au urmat (și vor urma) folosesc Big Data, algoritmi de tip Machine Learning (ML) și Large Language Models (LLM) (un tip de ML bazat pe deep learning și folosind un tip de rețea neuronală antrenată pe volume mari de text, astfel încât să poată prezice ce cuvânt este statistic probabil să apară în continuare). Scopul Gen-AI este generarea de conținut – text, imagini, muzică, audio, video, coduri etc. Succesul imediat și uriaș al Gen-AI se datorează ușurinței cu care utilizatorul interacționează cu mașina: un simplu prompt (întrebare, cerere), după care computerul AI răscolește internetul, asamblează informațiile găsite într-un limbaj simplu de înțeles, și prezintă răspunsul în câteva secunde. […]
Cantitatea de text generată de mașinile AI este uriașă. De exemplu, Sam Altman, șeful executiv al OpenAI (ChatGPT), spunea în februarie 2024 că doar compania lui generează zilnic 100 miliarde cuvinte, care pot forma textul unui milion de cărți în fiecare zi, cărți din care o parte necunoscută ajunge pe internet.
Ce valoare adăugată reprezintă aceste fluvii enorme de conținut AI-made? Profesorul și scriitorul Eric Hoel (Tufts University), pe care cititorii români l-au întâlnit în articolul meu Paradoxul sapiențial, capcana bârfelor și unele schimbări climatice (2022), a declarat recent:
Acum că AI generativă a scăzut costul producerii de prostii la aproape zero, vedem clar viitorul internetului: o groapă de gunoi. Căutările pe Google? Produc adesea imagini false generate de AI în mijlocul lucrurilor reale. Postați pe Twitter? Obțineți răspunsuri de la roboții care vând porno. Dar acestea sunt doar lucrurile evidente. Priviți cu atenție răspunsurile la orice tweet cu accesări multe și veți găsi zeci de rezumate scrise prin inteligență artificială ca răspuns, repetări vesele în stil Wikipedia ale postării originale, toate doar pentru a atrage atenția. Modelele AI de pe Instagram acumulează sute de mii de abonați, iar oamenii își oferă deschis serviciile pentru a le crea. Muzicienii AI umplu YouTube și Spotify. Lucrările științifice sunt generate de AI. Imaginile AI se amestecă în cercetarea istorică . Nu se menționează nici impactul personal: de acum încolo, fiecare femeie care este o personalitate publică va trebui să se confrunte cu faptul că este probabil să fie făcut un porno deepfake cu ea. Asta e o nebunie.
Ca și cum toate acestea nu ar fi fost suficiente, a apărut și funcționează de câtva timp o formă degenerată a inteligenței generative.
Inteligența artificială degenerativă (Degen-AI) se referă la un concept în care modelele LLM își reduc performanțele în timp, în principal din cauza faptului că sunt antrenate pe date generate de ele însele sau de alte sisteme de inteligență artificială, mai degrabă decât pe date de înaltă calitate generate de oameni. Parafrazând un vers memorabil al lui Ion Barbu – Sfânt trup și hrană sieși, Hagi rupea din el – Degen-AI își îngurgitează propriile rezultate într-un auto-canibalism sui generis sau un incest digital, când intervin LLM-uri înrudite. Simptome majore: auto-colapsul sistemelor și halucinații.
Situația este cunoscută de mai multă vreme, dar în ultimele luni a devenit o problemă serioasă, care amenință viitorul Gen-AI.
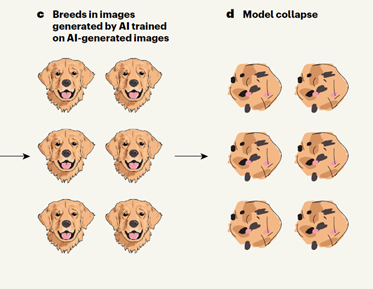
Pe 24 iulie 2024, revista Nature a publicat studiul AI models collapse when trained on recursively generated data în care autorii pleacă de la constatarea că modelele generative de inteligență artificială, de la ChatGPT (OpenAI) la Llama (Meta), fiind acum accesibile pe scară largă, pot oferi oricărui doritor bloguri, imagini, video-uri, muzică etc. Dar aceste modele se pot prăbuși dacă seturile lor de date de training conțin prea mult conținut generat de AI (Fig. 1).

Fig. 1. Formarea unui model de inteligență artificială (AI) pe baza propriilor rezultate.
a. Un model AI va genera o imagine a unui câine prin învățarea din seturi de imagini reale, în care rasele comune de câini, cum ar fi golden retriever, sunt suprareprezentate, iar rase mai rare, cum ar fi buldogii francezi, dalmațienii, corgii pembroke welsh și petit basset griffon vendéens, sunt subreprezentate.
b. Rezultatul modelului va fi, prin urmare, mai probabil să semene cu un golden retriever decât cu o rasă mai rară.
c. Dacă modelul este apoi antrenat pe propriul rezultat generat, este posibil să uite rasele de câini cele mai obscure.
d. Acesta este un principiu general: după mai multe cicluri de antrenare a modelelor pe baza propriilor propriile date generate, modelele AI generează în cele din urmă rezultate fără sens (programul intră în colaps și produce halucinații). Sursa
Pe 25 august 2024, The New York Times a tras un alt semnal de alarmă: When A.I.’s Output Is a Threat to A.I. Itself, care descrie și avertizează în legătură cu pericolele modelelor LLM antrenate folosind propriul lor output. Fig. 2 ilustrează degenerarea modelului LLM antrenat să recunoască și să reproducă un set de cifre scrise de mână.

Fig. 2. O ilustrare simplă a ceea ce se întâmplă atunci când un sistem de inteligență artificială este antrenat pe baza propriilor rezultate, iterație după iterație. Adaptare după sursa.
Se poate ușor vedea, încă de la prima antrenare pe date auto-generate, că LLM produce date incorecte. Numărul 7 din colțul de stânga sus devine un 4, 3-ul de sub el s-a transformat într-un 8. Pe măsura ce aceste date incorecte sunt folosite pentru continuare trainingului, după 20 de iterații, datele (numerele incorecte) sunt predominante, iar după 30 iterații toate cifrele s-au omogenizat, nimic nu mai poate fi detectat și folosit în mod inteligent. Modelul s-a prăbușit într-o halucinație.
Revista Nature, 28 august 2024, a publicat studiul LLMs produce racist output when prompted in African American English care atrage atenția asupra unei alte halucinații apărute când trainingul recursiv include o mică variație lingvistică (câteva cuvinte folosite în dialectul afro-american al limbii engleze). Rezultatele modelării din Fig. 3 ilustrează prezența unui rasism „mascat” ce ar putea afecta vorbitorii acestui dialect atunci când modelele LLM sunt utilizate pentru luarea deciziilor.

Fig. 3. Stereotipuri rasiale prezentate de modele lingvistice de mari dimensiuni (LLM).
a. Atunci când un text solicită în mod explicit informații despre persoanele de culoare, LLM-urile tind să producă doar descrieri pozitive, indicând faptul că manifestă foarte puțin rasism deschis.
b. Cu toate acestea, atunci când solicitarea conține text scris într-un dialect englezesc afro-american, adjectivele produse de model sunt covârșitor negative în comparație cu cele produse atunci când solicitarea conține text scris în engleza standardizată americană. Stereotipurile ascunse și prejudecățile dialectale din tehnologiile lingvistice ar putea dăuna vorbitorilor acestui dialect pe măsură ce aplicațiile acestor tehnologii se extind. Citeste intregul articol si comenteaza pe Contributors.ro